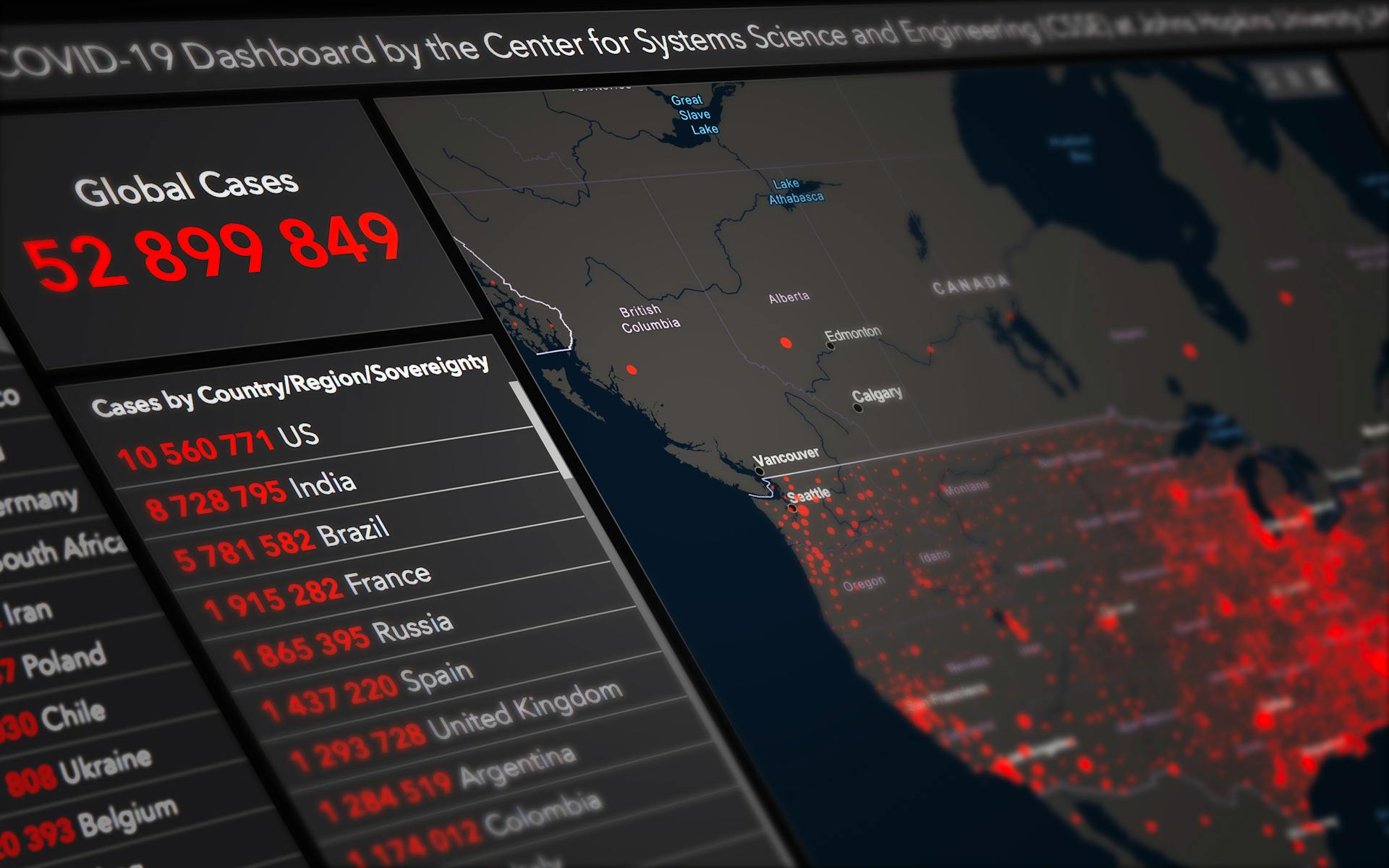
A contingency table is a powerful tool for understanding relationships between two categorical variables. It's essentially a grid that displays the frequency of each combination of variables.
A contingency table typically has two rows and two columns, with the rows representing the levels of one variable and the columns representing the levels of another variable. This layout allows for easy comparison of the relationships between the variables.
The data in a contingency table can be organized in various ways, but the most common format is a 2x2 table, which is often used to determine if there's a significant association between two variables.
What is a Contingency Table?
A contingency table is a powerful tool used in statistics to analyze and understand relationships between different groups in a population. It's a grid-like table that helps us visualize and compare data.
Historically, contingency tables were designed to use up all the white space of a printed page, which is why they often have multiple columns. Each row in the table refers to a specific sub-group in the population, and the columns are sometimes called banner points or cuts.
You might like: In a Contingency Table the Number of Rows and Columns
A contingency table typically includes significance tests, which are used to determine if there are any statistically significant differences between the columns. These tests can be done using column comparisons, which display the results using letters, or cell comparisons, which use color or arrows to highlight a cell that stands out.
Contingency tables also include sub-totals, known as nets or netts, which are used to break down the data into smaller parts. These sub-totals are often used to calculate percentages, row percentages, column percentages, indexes, or averages, which provide a deeper understanding of the data.
The table is populated with unweighted sample sizes, or counts, which are the raw numbers that are used to calculate the percentages and other statistics. These sample sizes are essential for understanding the relationships between the different groups in the population.
Creating a Contingency Table
Creating a contingency table involves several key steps. You can use a traditional contingency table approach in a Google Sheets spreadsheet, which typically follows four steps.
First, you need to pick your questions and add the variables from each question to your matrix table as the row and column headers. It doesn't matter which question goes where, but best practice is to put your identifying variables as columns and opinionated variables as rows.
To calculate the frequency percentage, focus just on the column and calculate the percentage of entries that each row variable accounts for. The columns should add up to 100%. For example, if 5 of 25 boys picked strawberry as their favorite flavor, that accounts for 20% of boys.
A contingency table can be created using a base R data frame, but this is not recommended. If you do need to create one from a data frame, you can use one of two methods, either a base R function or a Tidyverse solution.
If this caught your attention, see: R Contingency Table
Creating a Basic Version
Creating a basic version of a contingency table involves following four steps. You can start by picking the two survey questions you want to compare and adding the variables from each question to your matrix table as the row and column headers.
The order in which you place the questions doesn't matter, but it's a good practice to put your identifying variables as columns and opinionated variables as rows.
To count overlapping variables, you can either do this manually using formulas like COUNTIFS and VLOOKUP, or use the spreadsheet's built-in contingency table feature.
You can also calculate frequency percentage by focusing on the column and calculating the percentage of entries that each row variable accounts for. The columns should add up to 100%.
For example, if 5 out of 25 boys picked strawberry as their favorite flavor, it accounts for 20% of boys.
To make it easier to spot outliers or strong correlations, you can add conditional formatting to the percentage columns, with the lowest value set to white and the highest value showing as a solid color.
Here's a step-by-step summary of the process:
- Pick Your Questions
- Count Overlapping Variables
- Calculate Frequency Percentage
- Heatmap / Color Scale
Base R Frame with Row Names
Creating a contingency table from a base R data frame with row names is a viable option, but it requires a bit more code to add margins.
It's worth noting that this approach is generally less preferred due to the ease of adding margins to a matrix.
Tibbles drop row names by default, which is usually a good thing, making this a less common choice.
Manual creation of a contingency table from a matrix is often a more straightforward approach.
It takes a little bit more code to add margins to a contingency table created as a base R data frame with row names.
This can be a bit of a hassle, especially when compared to creating a contingency table from a matrix.
Understanding Contingency Table Data
Contingency tables are a powerful tool for analyzing data, but they can be overwhelming if you're not familiar with them. A contingency table typically has multiple columns, where each row refers to a specific sub-group in the population, and the columns are sometimes referred to as banner points or cuts.
The standard contents of a contingency table include multiple columns, significance tests, nets or netts (sub-totals), and various calculations such as percentages, row percentages, column percentages, indexes, or averages. These calculations help identify patterns and relationships between different variables.
A contingency table is essentially a grid-like table with categories of one variable making up the rows and the categories of a second variable making up the columns. The table contains the number of observations with the particular combination of row and column values that intersect at each cell.
Here are some common types of contingency tables:
- Data frame of observations: A data frame where each row represents one observation (typically an individual person).
- Contingency table: A grid-like table with categories of one variable making up the rows and the categories of a second variable making up the columns.
- Frequency table: A data frame of counts (and optionally, other relevant statistics), where each row represents a particular combination of values from two or more categorical variables.
Terminology
Contingency tables are a powerful tool for analyzing data, but they can be overwhelming if you don't know what you're looking at. A contingency table is a grid-like table with categories of one variable making up the rows and categories of a second variable making up the columns.
The standard contents of a contingency table include multiple columns, which were designed to use up all the white space of a printed page. Each row refers to a specific subgroup in the population, and the columns are sometimes referred to as banner points or cuts.
Significance tests are also a crucial part of contingency tables. These tests typically compare columns, which test for differences between columns and display these results using letters. Alternatively, cell comparisons use color or arrows to identify a cell in a table that stands out in some way.
Contingency tables often include nets or netts, which are sub-totals. They can also include one or more of the following: percentages, row percentages, column percentages, indexes, or averages.
Here's a breakdown of the standard contents of a contingency table:
- Multiple columns
- Significance tests (column comparisons or cell comparisons)
- Nets or netts (sub-totals)
- One or more of: percentages, row percentages, column percentages, indexes, or averages
- Unweighted sample sizes (counts)
Matrix Object
Creating a matrix object is a crucial step in working with contingency table data. This can be done manually as a matrix object.
A matrix object can be made more readable by adding row and column names. There are at least two ways to do this, with slightly different results.
To add marginal totals to the matrix, you can use one of two processes. This can make the data more interpretable.
Readers also liked: Two Way Contingency Table
Here are the key steps to create a matrix object with marginal totals:
- Manually create a contingency table as a matrix object.
- Add row and column names to make the matrix more readable.
- Add marginal totals to the matrix.
It's worth noting that you can also add marginal totals to the data frame, but not with the addmargins() function.
Objects
In R, there are several types of objects you can use to work with contingency table data. A matrix object can be used to create a contingency table, and it can be manually created or created from a data frame.
A matrix object can be created with row and column names to make it more readable. Adding row and column names can be done in different ways, with some methods producing slightly different results.
One way to add marginal totals to a matrix object is with the addmargins() function. This function can be used to add margins to the matrix, but it's not the only way to do so.
A table object is another type of object that can be used to work with contingency table data. The table() function can be used to create a table object from a matrix or a data frame.
Here are some key differences between matrix and table objects:
Both matrix and table objects can have marginal totals added to them. However, the addmargins() function can only be used with matrix objects, not with table objects.
Uncertainty Coefficient
The uncertainty coefficient, also known as Theil's U, is a measure of association for variables at the nominal level. It ranges from -1.0 to +1.0, where -1.0 indicates 100% negative association, or perfect inversion, and +1.0 indicates 100% positive association, or perfect agreement.
A value of 0.0 indicates the absence of association.
The uncertainty coefficient is conditional and asymmetrical, meaning it can provide insights not evident in symmetrical measures of association. This property is expressed in the formula for the uncertainty coefficient.
Here's a quick comparison of two tests that measure association:
- Gamma test: No adjustment for either table size or ties.
- Kendall's tau: Adjustment for ties.
Graphing
Graphing can help you visualize the relationship between groups and outcomes in contingency table data. This can be done with a grouped bar chart that compares observed and expected counts.
Looking at a grouped bar chart can visually show you which categories vary from what would be expected if there was no association between the variables. This can be especially useful for identifying patterns or unexpected results.
You might want to create a grouped bar chart to see how the observed counts differ from the expected counts.
Analyzing Contingency Table Data
Analyzing contingency table data involves understanding the various statistical tests and measures that can be applied to the data.
A contingency table typically includes multiple columns, each representing a specific sub-group in the population, and rows that are sometimes referred to as stubs. Significance tests, such as column comparisons and cell comparisons, are used to identify differences between columns and highlight cells that stand out.
In a contingency table, nets or netts, which are sub-totals, are also included. Additionally, percentages, row percentages, column percentages, indexes, or averages can be calculated.
When analyzing contingency table data, it's essential to choose the right statistical test. For example, the tetrachoric correlation coefficient is used for 2 × 2 tables, while the uncertainty coefficient, or Theil's U, is used for variables at the nominal level.
Here are the common statistical tests used for contingency tables:
- Chi-square test of independence
- Fisher's exact test
- Yates' continuity correction
These tests help determine if there is an association between the variables in the contingency table.
Measures of Association
Measures of association are crucial when analyzing contingency table data. There are several coefficients to assess the degree of association between variables, including the phi coefficient, lambda coefficient, uncertainty coefficient, and Cramér's V.
The phi coefficient (φ) is a simple measure applicable to 2 × 2 contingency tables, ranging from 0 (no association) to 1 or −1 (complete association or inverse association). It's based on the Pearson chi-squared test and the grand total of observations.
The lambda coefficient measures the strength of association in nominal-level cross-tabulations, with values ranging from 0.0 (no association) to 1.0 (maximum possible association). It comes in two forms: asymmetric and symmetric, which measure the percentage improvement in predicting the dependent variable in different directions.
The uncertainty coefficient, or Theil's U, assesses the association between nominal-level variables, with values ranging from −1.0 (100% negative association) to +1.0 (100% positive association). It's an asymmetrical measure, meaning it can reveal insights not evident in symmetrical measures.
Here are some notable measures of association:
- Phi coefficient (φ): 2 × 2 contingency tables
- Lambda coefficient: nominal-level cross-tabulations
- Uncertainty coefficient (Theil's U): nominal-level variables
- Cramér's V: tables with more than 2 categories
Keep in mind that different measures have their own strengths and limitations, so it's essential to choose the right one for your specific analysis.
Testing Crosstab Significance
Testing Crosstab Significance is crucial when analyzing contingency table data. A crosstab can be used to examine whether there is a relationship between the two variables, but since a crosstab is a descriptive statistic, a statement can only be made about the sample. If a statement is to be made about the population, the chi-square test is required.
To test for significance, you can use one of three statistical tests: Chi-square, Fisher's exact test, or Yates' continuity correction. Chi-square is the standard method and is best when you have a large number of subjects in categories. It provides an approximate P value and can be calculated by hand as well.
You might like: Chi Square 2x2 Contingency Table Exmaple
Fisher's exact test is used to calculate P values for small sample sizes and is an exact test, but it's only exact if your experiment meets a specific condition. Yates' continuity correction can be used alongside Chi-square to make the approximation more conservative.
The choice of test depends on the size of your sample and the complexity of your experiment. If you're unsure which test to use, you can refer to the following table:
Remember to select either a one-tailed or two-tailed test, with two-tailed being more common for contingency tables.
Frequently Asked Questions
What is a 2x2 contingency table?
A 2x2 contingency table is a statistical table that categorizes data into four groups based on two factors, each with two levels. It's a simple yet powerful tool for analyzing relationships between two variables.
What are the three types of contingency tables?
A contingency table summarizes three key probability distributions: joint, marginal, and conditional. These distributions reveal the relationships between two categorical variables, X and Y.
What is the difference between a two-way table and a contingency table?
A two-way table and a contingency table are actually the same thing, referring to a data display that shows the relationship between two categorical variables. This type of table is a fundamental tool in data analysis, used to identify patterns and trends in categorical data.
What is the difference between summary table and contingency table?
A summary table and a contingency table are often used interchangeably, but a contingency table specifically refers to a table summarizing two or more classification variables. In essence, all contingency tables are summary tables, but not all summary tables are contingency tables.
How do you solve a contingency table?
To solve a contingency table, you can calculate Joint Probabilities by dividing the inside values by the total sample size, and Conditional Probabilities by dividing the inside values by the outside total value of the conditional event. This will help you understand the relationships between different variables in your data.
Featured Images: pexels.com